
1月20日,地平线在智东西公开课开设的「地平线AI芯片技术专场」顺利完结。在本次专场中,地平线BPU算法负责人罗恒博士就《怎么样打造一颗好的无人驾驶AI芯片》这一主题进行了直播讲解。
罗恒博士围绕AI计算需求量开始上涨带来领域专有架构芯片、无人驾驶软件算法方案、从无人驾驶软件算法方案看对AI芯片的要求、一些设计无人驾驶AI芯片的实践四部分进行了深入解读。

大家好,很高兴和大家一起探讨地平线在无人驾驶芯片设计方面的一些想法。我是罗恒,2011年博士毕业于上海交通大学,博士期间一直在做深度学习方面的研究,后随图灵奖获得者Yoshua Bengio进行博士后研究;2016年加入地平线,做 BPU算法、工具链相关的产品研制工作,先后推动了中国首款边缘AI芯片、首款车规级芯片的诞生。车规级芯片在2020年获得了“第十届吴文俊人工智能专项奖”芯片项目一等奖。
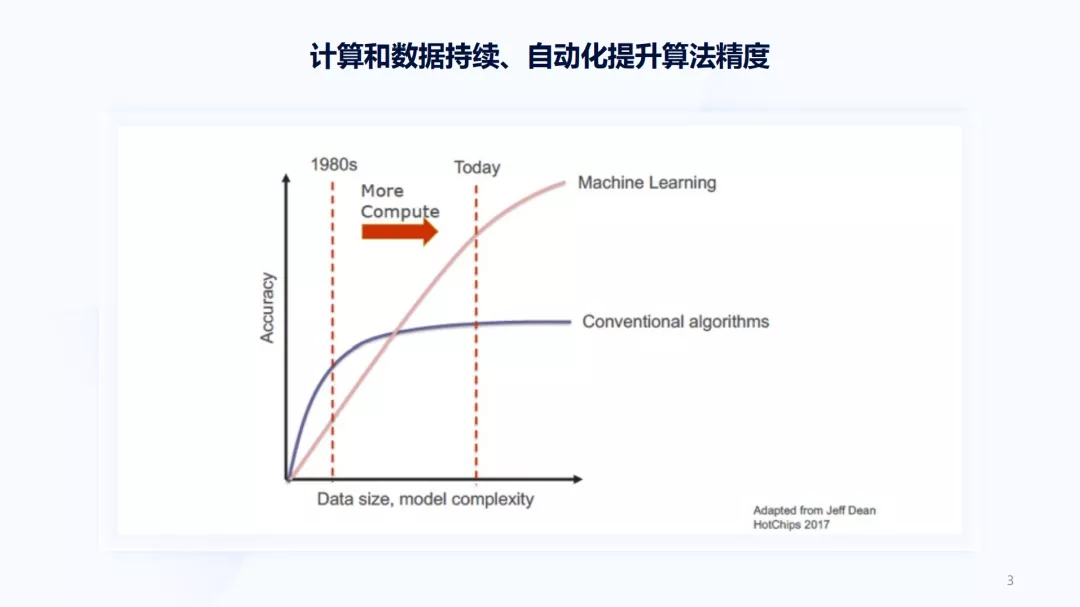
首先,想和大家讲下Jeff Dean在2017年的一张图。这张图解释了AI为什么是可能的。AI有两种算法:一种是传统算法,如上图的紫线部分,随着数据量、模型复杂度的增加,准确度和精度很快达到了饱和,同时传统算法主要依赖于人工设计;另一种算法是机器学习或基于神经网络的算法,这类算法当数据量少、模型小时,可能不如人工设计的算法精度高,但随着数据和计算的增加,它的精度会持续上涨。目前,大多数的AI任务并未达到饱和,只要数据量越多、模型越大,性能就可能持续提升。
上图纵轴的精度表示一个模型的精度,如果模型能代表一个软件的功能,则能持续提升软件的功能。例如抖音,它的数据非常容易获取,只需浏览它时就会捕获到数据,而当你不去刷它,则会一直播放当前的内容。这是它在强迫你给一个反馈,然后利用这些反馈在云端进行大量计算来估计你的喜好,而估计你的喜好就是模型的结果,即软件功能本身。当慢慢的变多用户使用抖音时,云端获取计算变得很容易,就能持续提升模型的精度,也在持续提升软件功能。
在抖音或其他互联网应用中,由于问题是被充分定义的,所以它们其实就是一个相对简单的任务。但无人驾驶不同,虽然无人驾驶也会用到各种各样的模型,但这些模型无法直接对应到最终的功能。即使能持续提高模型的精度,但能否持续提高无人驾驶的功能仍是一个问题。例如特斯拉,它以端到端的方式持续不断的发展,就希望能用一个模型,代表软件的功能,然后利用数据与计算持续优化无人驾驶的功能。
自动驾驶是AI计算中的一种,这些年AI计算的需求量开始上涨非常快,带来了大量的领域专有架构芯片,它们与以往CPU有明显的区别。但这些AI计算芯片也面临着巨大的挑战,表现在无人驾驶的软件算法方案并没有收敛,即使是在同一个企业,软件算法方案也在持续的迭代、变化。从这些软件算法中也能够准确的看出对AI芯片的需求,而算法本身也在高速演进,然后结合以上这些来看下我们是如何思考、设计无人驾驶AI芯片的。因此,本次讲解内容大致上可以分为以下4个部分:

上图中的右部分横轴表示时代,2012年AlexNet第一次赢得了ImageNet比赛,并开启了一轮AI热潮的序幕。纵轴表示训练这些模型所需的时间,能够正常的看到呈现出数量级的增长,7年之间对算力的需求增加了6个数量级。但同期的左边图,表示通用计算,即CPU,它的上涨的速度则在迅速放缓,在摩尔定律发挥作用时,最快每一年半计算性能提升一倍。但现在,已经从每6年翻一倍,增加到每20年翻一倍,所以CPU注定没办法提供 AI算力。
当计算需求远远超出摩尔定律和以往人类提升算力、增加计算的速度时,该如何呢?我们得知机器学习和神经网络绝大多数是线性代数的加速运算,而它们相较于一个通用的编程语言,加速的可能性和并行性空间非常大。举一个矩阵乘的例子,如果用 Python运行矩阵乘的速度为1,当利用一个更具机器学习特性的C语言去编写,速度提升了47倍;如果再把一些循环并行起来,能提升到300多倍;如果对存储做一些优化,提升到6000多倍,最后在硬件上对向量的计算增加一些加速指令,则能提高到6万多倍。从1到6万多倍的提升,就来自于对特定问题的深刻理解。
有了巨大的需求,也有了相应的解决方案,整个行业都开始高歌猛进,朝着 AI专用加速器的方向发展。代表性的产品是2015年谷歌在自有数据中心使用的高度定制化AI推理芯片TPU。2019年,计算需求已经从最早的云端到了自动驾驶领域,特别是特斯拉慢慢的开始使用自有高度定制化的AI推理芯片FSD。同时,2019年全世界已经约有100家组织推出或正在研发AI推理芯片,这一个数字到现在可能变得更大。
由于如何设计与如何评估这些芯片是紧密联系在一起的,所以正确的设计/评估这些芯片可以从以下三方面考虑:
其次,芯片是一个物理的实现,它对成本和功耗限制不同,由于目前只有少量的 AI任务实现收敛,算法本身也在持续迭代;
最后,AI算法本身并不是跑得越快越好,不同的算法还存在准确率的问题,要同时考虑到快和准。
把上面三点放在一起最大限度地考虑,能够对设计和评估这些芯片有更深刻的认识,就可以在设计中做出取舍。
地平线月成立,是中国第一家AI芯片勇于探索商业模式的公司。地平线的定位是在边缘做 AI芯片,企业定位不同的背后是需求不同。像英伟达、华为、谷歌,它们的整体架构设计,主要面向数据中心,而数据中心往往处理海量数据,需要高吞吐率和限定时间的响应;并且在云端,AI任务种类非常之多,基本上各类任务在云端都能够找到;但在云端,任务本身是限定在虚拟世界,是一个封闭的、定义单纯的任务,所以模型加速就是最核心的负载。
相较于数据中心,无人驾驶的需求会非常不同,这些不同的需求也导致了设计上取舍的不同。比如对无人驾驶而言,无论采用什么样的技术路线,有一个事实是无法回避的:处理的数据是流数据,即数据源源不断的通过种种传感器到达车上,这时必须对数据来进行马上处理,而且延迟越低越好。延迟越低就越能根据周围的情况作出反应,及时刹车并控制车量,来保证安全。
从设计上来看,我们的芯片和特斯拉FSD,都是面向Batchsize=1去优化的。而 GPU以及其他一些以云为核心业务的公司,设计的AI芯片往往需要比较大的数据量,数据积累比较多,才能把芯片利用率发挥的更好。
对无人驾驶而言,尽管现在有各种各样的传感器,但从计算的角度来看,核心是计算视觉,主要有两个原因:第一个原因是整个物理世界是一个语义的世界,自动驾驶汽车需要识别出前面的交通标志牌、车道线,以及障碍物是普通障碍物,还是随时会动的障碍物,这都是语义的问题,不可能通过视觉以外的其他方案得到解决;第二个原因是视觉能带来最大量的数据,其他传感器每秒获得数据量比摄像头获得的数据相差了许多数量级。同时,由于软件算法在持续重构中,往往需要不同的方案设计,因此就需要不同的加速方式,所以要最大限度地考虑AI加速与CPU、GPU、DSP的协调。在车上,成本、散热和云端也有完全不同的限制,由于车和人的生命安全相关,所以对它的可靠性要求也高。
下面从需求侧来看无人驾驶软件算法的挑战。首先是技术路线,在纯视觉方案中,主要以特斯拉为主。他们都以为视觉可提供了最大的冗余,而激光雷达或其他传感器提供的数据量很少,所以有可能会出现问题,但视觉数据量非常大,模型的健壮性非常好。在多类传感器融合的方案中,像国内的华为、小鹏等。除此之外,像 Mobileye,它希望能有两套感知系统来做冗余,当两套感知系统之间的相关性非常低时,就能极大提高总系统的安全性。
从行业上来看,即使是一个企业,软件算法方案也在持续变化,典型的例子是特斯拉。刚开始特斯拉使用Mobileye的方案来解决无人驾驶问题,之后开始自研算法转向使用 NVIDIA GPU,进一步发现 NVIDIA GPU无论在功耗、算力、成本上都不足以满足需求,之后自研了FSD芯片,并于2019年投入使用。
无论是放弃Mobileye,还是转向 NVIDIA,或是自研FSD芯片,每一次硬件的大幅改变,也会带来软件算法的大幅改变。去年特斯拉放弃了Radar,等于完全使用神经网络模型估计物体距离、加速度,这又是一次对软件算法的改变。再到去年的AI Day,多个摄像头的视频直接输入到模型里,然后通过模型最终输出时,已经是时空一致的结果。最近马斯克接受媒体采访时表示,特斯拉已完成了从视觉到向量空间的完整映射。
通过上面能够准确的看出,当设计一个无人驾驶AI芯片时,首先要对未来算法软件发展趋势做积极估计,同时也要尊重客户对不同方案的尝试,所以要在这些趋势中找大方向,找主要矛盾。

回到算法本身,算法也在迅速变化,而且算法的很多变化可能会对芯片设计带来一些致命的影响。像WaveNet,它的技术核心是把文本转换成人一样的语音技术,2016年由谷歌发明。刚出现时,这个算法对计算量的需求非常大,无法实时完成计算,也无法实时与人进行交互。当WaveNet算法做出了一些优化,计算效率提升了1000倍,这时GPU可以20倍实时运行,谷歌马上就把它产品化,并放在谷歌助手中。但这个算法只能在云端用,无法在端侧的AIoT场景使用。
这时谷歌公司想根据当时的WaveNet算法开发一个加速芯片,但2018年算法又一次演进,有数百倍的性能提升,这使得手机CPU能够运行WaveNet。而一个芯片的研发周期很长,芯片的研发一直到2019年才完成,后续也没听到这个芯片的量产情况。这是一个极端的例子,所以想提醒的是算法在持续变化,我们应该对未来做判断。
我们最关心的是视觉,视觉中最重要的是卷积神经网络。卷积神经网络从上世纪90年代诞生到现在,总体发展不像WaveNet那么快。人们看到的是一张图,而机器看到的是一个矩阵,矩阵里面的像素点表示像素强度、多个Channel 、RGB等。卷积的运算是把输入图像转化为一张可以被机器理解的图,在整个卷积神经网络运算的过程中,分辨率在不断下降,Channel数在不断增多,本质上是不断的看图像更大范围,然后把更大范围用一个点来表示,即把图像高度抽象化,并从不同层面解释这张图。
目前,卷积神经网络对于AI、无人驾驶是一个最重要的模型。特斯拉公开表示,它的模型中卷积的计算量占比达到了98%。卷积的计算过程是利用卷积核中的一组参数,这组参数会扫过图像中的每一个像素点,然后把输入值和参数值点对点相乘,之后累加相乘得到最后的结果。尽管它是一个很简单的计算,但由于卷积本身有各种变形,网络结构在深度、宽度等各方面也做变形,卷积层之间也有不同的连接方式,以及使用各种各样的激活函数,因此能产生了各种各样的卷积神经网络。
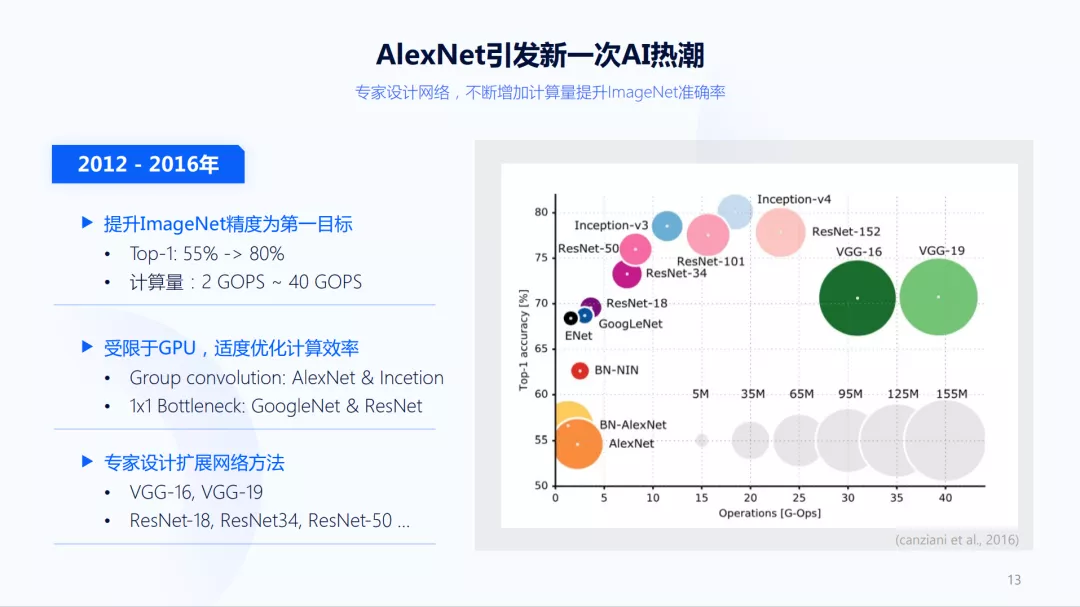
如上图右边所示,每个圈代表一个卷积神经网络,横轴表示卷积神经网络要多少计算量,纵轴表示精度,圈表示模型参数量。因此能看到这些模型的表现完全不同,比如最右面的两个大圈,它们的精度可能刚过70%,但它们所需的计算量和其他网络有很大差别,也就是当硬件对所有网络加速完全一致时,得到同样的精度,使用右边模型需要10倍的时间。
而这一时期整个学术界纷纷转向ImageNet,算法精度也随之不断提高。除了右边两个绿圈比较特殊之外,通常随着计算量的增加,精度也在不断上升。而到实际工作中也会面临这样的问题:需要在速度和精度之间找一个折中,这个时期怎么用一个更大的网络得到更好的精度,可以考虑一些专家设计的网络扩展方法。
对于神经网络来说,给它更多的数据和计算,准确性就会迅速提升。从2012年AlexNet第一次参加ImageNet开始,到2017年比赛最后一界,卷积神经网络的精度已经非常高。这时开始寻找在同样的精度下,如何去减少计算,提升模型的效率,出现了一系列有代表性的模型:SqueezeNet、MobileNet、ShuffleNet。这时也出现了卷积神经网络产生以来最重要的一次变化:Depthwise Convolution。另外一个变化是需要在模型的计算量和精度上找折中的方式,这时可以开始在小范围内开始寻找,并使用一些自动化的搜索。
2019年,随着EfficientNet的出现,我们认为卷积神经网络结构的演进暂时进入一个平缓发展的阶段。为什么?因为在卷积发展的二十几年中,出现了Depthwise Convolution,而传统算法都是人工设计的模型结构,再到机器设计的模型结构,这也是一个大的变化。这两个大的变化被很好的结合在EfficientNet中,由此我们认为卷积出现新变化的可能性比较少。这个观点在2019年EfficientNet发表时,我们就已经是看到了,到目前为止,这个观点依旧可靠。
接下来是 Transformer,Transformer实际上是一个非常特别的神经网络,卷积神经网络通过一层一层的卷积,并经过很深的层数后,在feature map上的一个点,可以看见原图一个更大的区域。以识别建筑物为例,如果想识别出建筑物,不仅仅需要看到有窗户,可能还需要看到房顶、天空、地面之间的关系,它们之间是一个长距离的相关性。当天空、草地、窗户等同时符合一定的空间规律时,才能定义这是一个建筑物或庄园。
Transformer来自于自然语言处理,机制是从输入一开始就计算任意两点之间的相关性,即每一层计算都可以直接计算很长距离之间的两两相性,这个能力是CNN不具备的,而它对于理解图像很关键。因此, Transformer在实际应用中也表现了巨大的潜力,但仍存在一个问题:Transformer在视觉任务中很难定义基本单元是什么。基本单元可以很大,也可以很小,像高分辨率语义分割中,基本单元可以是像素级别,而在做一些物体识别时,基本单元可以是车、行人等大的物体。
Transformer在计算任意两点之间的相关性时,会产生非常大的计算量。如果不计算点和点之间的相关性,而是限制计算patch和patch之间的相关性,如果patch设置太大,一些精细的相关性会被忽略,如果patch设置太小,计算量又太大。Transformer等类似工作采取的方式是限制计算相关性的范围,即限制 Self-Attention的范围,无需与全图计算相关性,只需与一些局部进行计算。好处是计算效率得到了保障,坏处则是 Transformer相对于CNN最大的特别性受到了限制,而这个限制一定程度上受限于GPU,因为在很远距离两两计算的计算架构上,GPU不太友好。
总之, Transformer相对于卷积神经网络有全新的特性,但这个全新的特性并没有很好的发挥出来,所以短期之内还是以卷积神经网络为主,Transformer则提供一些特殊的作用。比如特斯拉,它需要把多路摄像头的视频最终融合到一起,得到一个完整的向量空间表示,而对于不同摄像头数据输入到模型之后的特征融合,使用 Transformer是一种非常好的方法。
那过去设计的芯片是否无法使用呢?Transformer本质上大部分计算依然是矩阵乘,所以现有的AI芯片都可以对它进行加速。而真正挑战则是各种 local attention的方式,这对于灵活的数据存取有挑战。
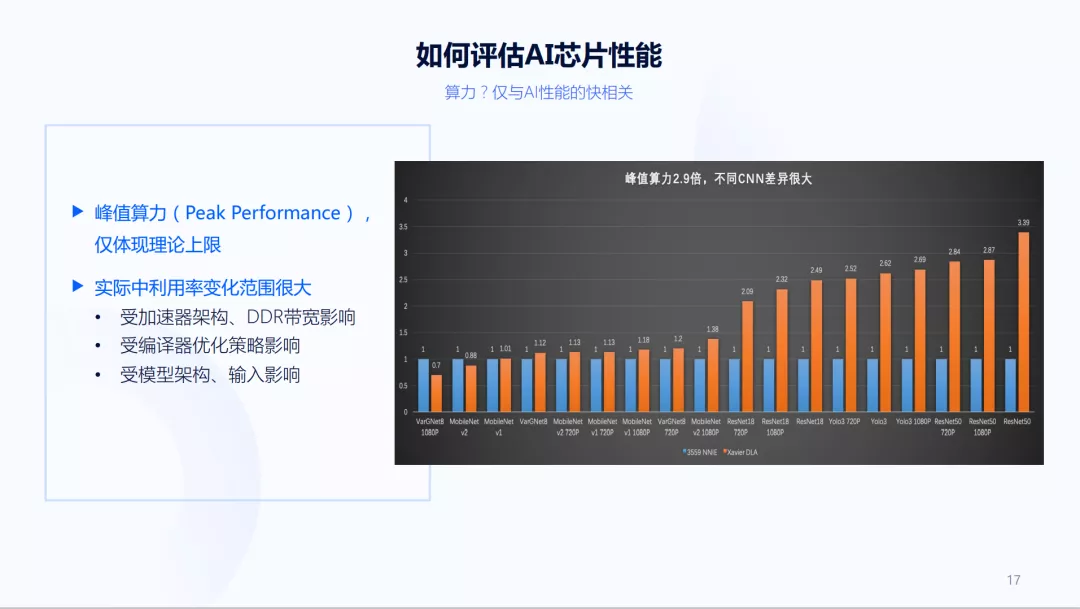
上面介绍了许多外部的需求,当真正有了芯片之后,该如何评估芯片的性能?如何设计它?这通常是一个峰值算力的问题。但仅凭峰值算力还无法真正体现芯片性能。像上图,两个AI加速器的峰值算力相差几倍,但在不同模型中实际运行时,结果有时差不多,有时差距很大。所以,一个大算力芯片不一定跑得很快,而一个小算力芯片不一定跑得很慢。它们受加速器架构、 DDR带宽、编译器优化策略、模型架构、输入大小与对齐情况等各方面的影响。
当计算这么多的模型时,如果知道哪个模型最重要,这个问题会变得比较简单。对自动驾驶而言,什么样的视觉任务最重要呢?自动驾驶的核心是识别周围有哪些物体、它们是什么、它们的属性是什么、与车辆的距离如何,也需要识别一些小物体,即识别远处的物体,所以核心负载是一个高分辨率的物体检测问题。同时,数据是流数据,即数据需要马上要处理,所以它也是一个Batchsize=1的高分辨率物体检测。
选用在COCO数据集上运行各种各样的算法,无论是在我们的芯片上,还是在GPU上,EffcientNet在同样精度下都能达到最快的速度。尽管 GPU对EffcientNet的支持并不友好,但是EffcientNet使用的计算量仍比ResNet少七、八倍。

上图是评估的结果,横轴表示帧率,纵轴表示精度。橙色的线表示在Xavier上运行的结果,能够正常的看到在相对精度比较高时,Xavier能够提供的帧率非常低,但在实际应用中,精度还需要更高,另外需要处理多路的摄像头,而多路摄像头的分辨率往往比COCO还高,这也是为什么Xavier无法很好的支持自动驾驶方案,也是为什么特斯拉要自研芯片。
黄色线是我们估计出来的Orin结果,这里的估计方法一方面结合NVIDIA对Orin算力的公开信息,以及对Orin相对Xavier能力提升的描述;另外一方面根据NVIDIA RTX3090,因为NVIDIA RTX3090与Orin都使用安培架构,我们会从中对利用率做一些调整。从总体评估结果来看,我们的AI芯片相对于Orin提升是非常明显的。如果把不同精度下的帧率平均,大约是Orin的两倍;功耗上看,我们的芯片只有20瓦,Orin的功耗是65瓦;从能效上来看,我们有6倍多的提升。
那怎么设计AI芯片呢?地平线是一家算法基因的公司,与别家企业做AI芯片的最大不同是我们大家都认为算法是动态的、不断变化的,我们随时都在预估未来的趋势,同时我们又是一家芯片公司,并不仅仅看算法本身,更看重算法对计算架构的影响,这也使得在Depthwise Convolution刚推出时,能够迅速的关注到它。仅从算法的表现来看,Depthwise是最核心的计算单元发生改变。如果结合到芯片,可以发现它对计算的需求很不同。
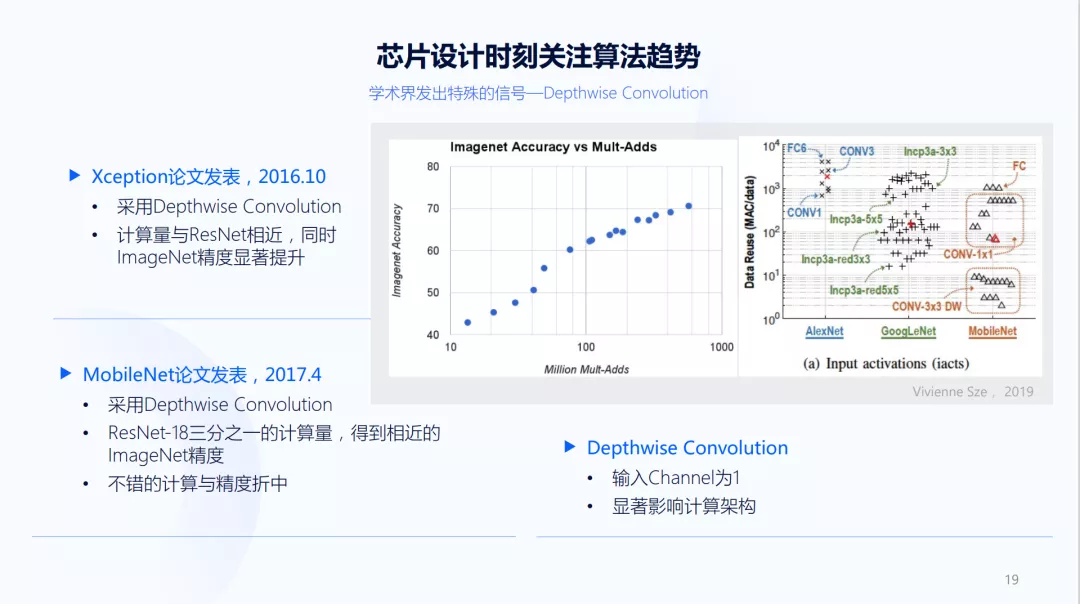
2019年,学术界对AlexNet、GoogleNet和MobileNet三类的模型做了分析,如上图所示,横轴的不同点表示三个模型,纵轴是数据复用的情况。数据复用率越高时,对模型加速带宽要求是不同的。从上图可以看到MobileNet和其他两个模型是非常不同的,有两个数量级的差别,这些不同是会显著影响计算架构。
因为有算法背景,并关注算法发展趋势,所以我们是结合计算来看算法,因此能够在第一时间识别出哪些方面对计算架构有重大的影响,而且它有可能变为未来非常高效率的算法。同时,地平线也是一家软硬结合的公司,不会仅仅满足在软件算法层面上的探讨,也会把它做进硬件,使得芯片效率最大化。
软件算法层面上,在2017年7月,我们发现当模型非常小时,精度的损失很大,因此我们设计了一套量化训练算法,利用量化训练解决Depthwise模型的精度问题,并申请了专利。而学术界到2019年,谷歌才推出相应的量化算法。现在我们的算法、硬件架构又在朝前演进,对于这类模型只需利用浮点模型转换。我们在工具链方面已经支持了100多家的客户,精度问题上也表现得很好。
同时,还有一些其他的考虑,比如Kernel Size,由于在传统卷积中扩大Kernel Size代价很高,但在Depthwise卷积中的计算量非常小,所以这种情况下,扩大Kernel Size代价非常低。根据在软件算法层面上的验证,我们做了FPGA上车实测,并把软件算法方案放进去,最终在2019年获得了CES创新奖。
下面回到无人驾驶场景本身。尽管技术路线、软件算法方案的演进各不相同,但也存在一些共性,像全数据链路考虑、精度和性能的折中、多模型的灵活调度等。除此之外,像无人驾驶要求检测精度很高,在评估软硬件算法方案时,IoU=0.9;当需要把远处的物体检测出来实现小物体检测时,要有高分辨率的输入;还有一些稳定性、高优先级任务抢占的要求等。同时,像一些语义分割任务,涉及许多高分辨率的输出,对带宽压力很大,需要对带宽要做压缩。此外,当无人驾驶为了适应光线强度的大幅变化时,需要融合激光雷达数据。有时还想使用ISP,但是不想要ISP的长延时,需要当ISP处理一部分时,BPU、AI加速提前启动,双方从overlap中往前走,这些都是我们的设计。
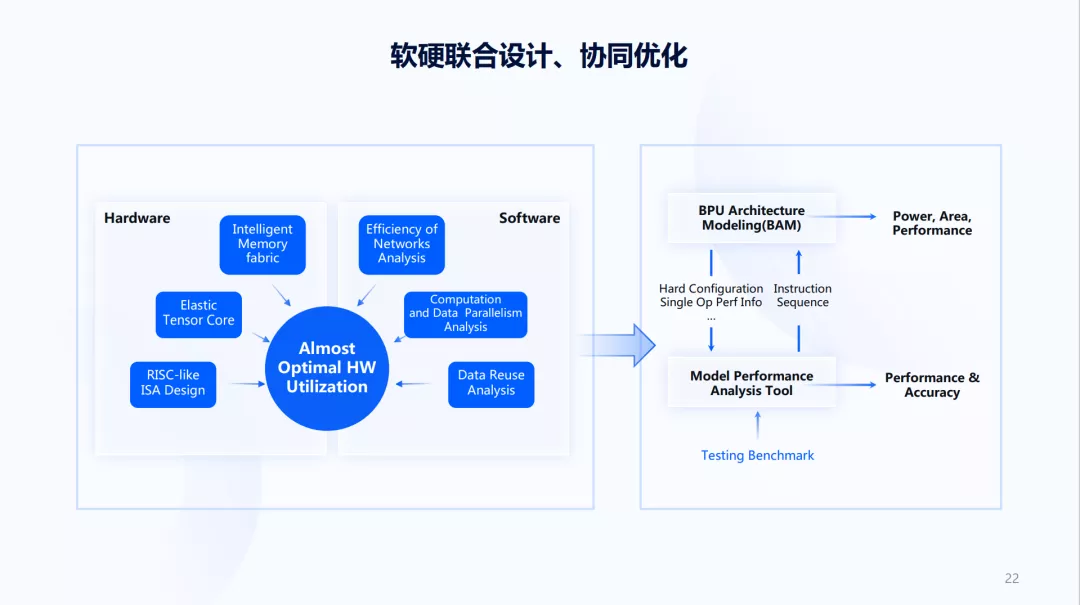
根据上面的内容可知,我们需要在一个更大的空间去设计AI芯片,具体做怎样做呢?我们经历了两个阶段,第一个阶段如上图左边所示,一半是硬件,一半是软件,我们希望把硬件和软件联合起来考虑。那怎么把它们结合起来呢?以前公司有几个团队,在右边工作的是软件团队、算法团队、编译器团队,软件团队主要看整体软件方案该怎样调度,各方面的性能瓶颈如何;算法团队主要看整个算法的发展的新趋势如何,有哪些可能性需要考虑;编译器团队在软件算法方案确定之后,进一步的分析数据复用的情况,对数据计算并行等做分析。
有了这些分析后,可以把更细节的要求给到硬件团队,然后硬件团队结合这一些细节要求做指令级的设计、做加速器的设计、做存储的设计。同时,硬件团队在设计过程中又会提出一些新的限制,随后软件团队再去思考双方如何配合,哪些是硬件团队做,哪些是软件团队做,如何既保持很高的效率,又保持未来的灵活性。
经过五六年的合作演化,从原来人和人之间的合作,慢慢变成现在的一些流程和工具,目前主要是上图右边的方式,软件算法团队主要工作在Benchmark,他们定义了哪些Benchmark是需要测试的。目前,大多分布在在模型层面,而更加完整的方案还在持续的向前推进。
Model Performance Analysis Tool层能够理解为一个简单的模拟器,也就是编译器团队以往人工的工作,现在变成了一个工具。编译器团队不再直接在一个个模型上工作,只要把工具做好,所有模型结果都能够获得。而它会得到两个内容,一个是硬件给它的各种限制,像硬件的各种配置、各种特性。有了这些之后,可以生成一个指令序列,这个指令序列在BPU Architecture Modeling的建模工具里,它一方面能够直接用一些高阶综合的方式得到功耗面积,另一方面利用这些指令流可以估计出性能。同时,Model Performance Analysis Tool模拟器也可以估计出性能和精度。
当有了这样一个工具,好处在于可以把Benchmark做得很大,而工程师们不再面向一个模型工作,而是面向一个工具工作。架构设计团队也可以有更多的选择,这些选择都是在少量编码的情况下,在更大的空间上完成各种软硬件的结合方案。
以上是我们设计AI芯片不同地方,一方面从需求、软件算法方案、算法演进出发,另一方面把软件、硬件充分结合,来联合优化目标。

